Responsible Disclosure of Generative Models Using Scalable Fingerprinting
ICLR 2022 Spotlight
1. Salesforce Research
2. University of Maryland
3. Max Planck Institute for Informatics
4. CISPA Helmholtz Center for Information Security
*Equal contribution
4. CISPA Helmholtz Center for Information Security
*Equal contribution
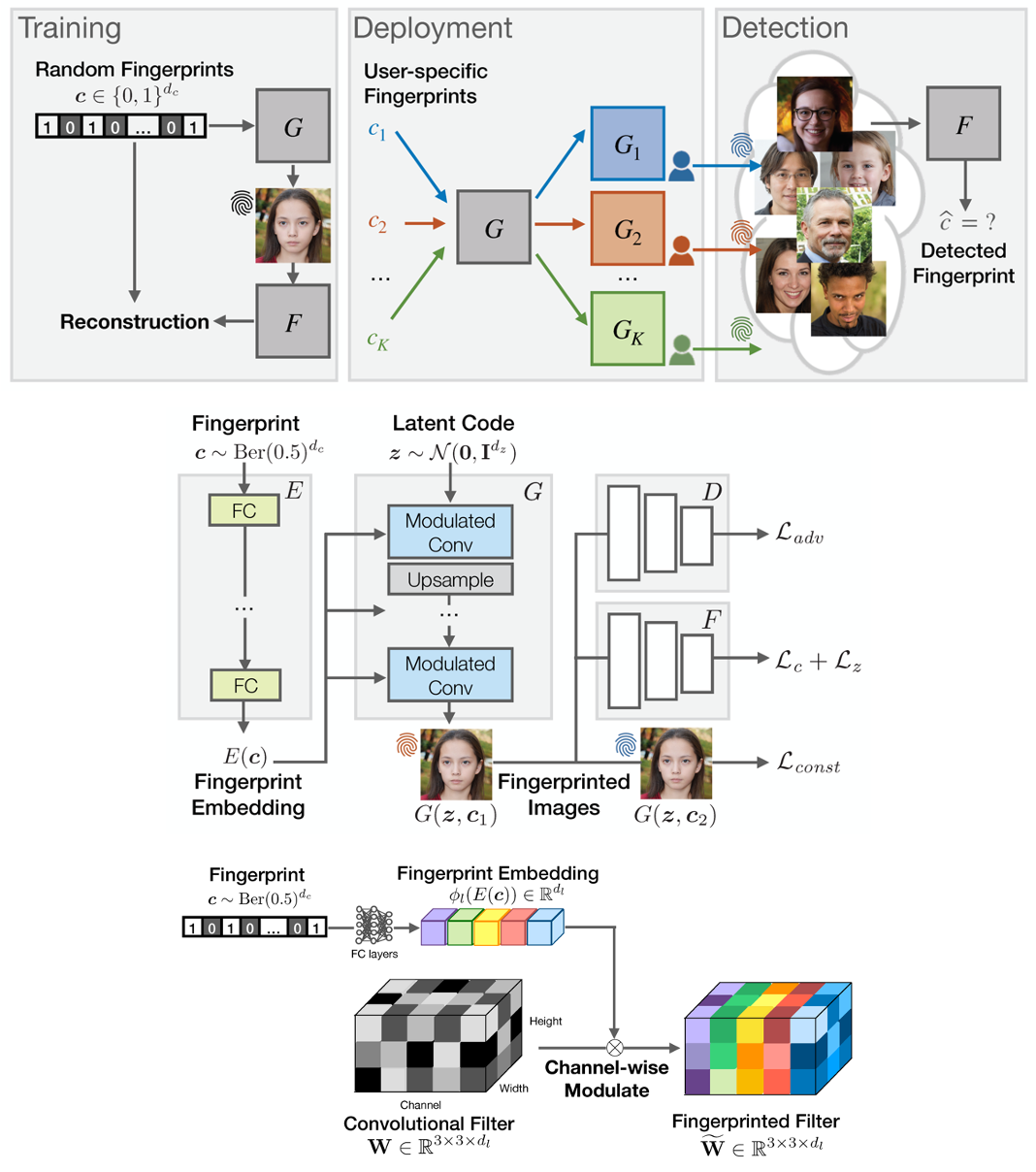
Abstract
Over the past years, deep generative models have achieved a new level of performance. Generated data has become difficult, if not impossible, to be distinguished from real data. While there are plenty of use cases that benefit from this technology, there are also strong concerns on how this new technology can be misused to generate deep fakes and enable misinformation at scale. Unfortunately, current deep fake detection methods are not sustainable, as the gap between real and fake continues to close. In contrast, our work enables a responsible disclosure of such state-of-the-art generative models, that allows model inventors to fingerprint their models, so that the generated samples containing a fingerprint can be accurately detected and attributed to a source. Our technique achieves this by an efficient and scalable ad-hoc generation of a large population of models with distinct fingerprints. Our recommended operation point uses a 128-bit fingerprint which in principle results in more than $10^{38}$ identifiable models. Experiments show that our method fulfills key properties of a fingerprinting mechanism and achieves effectiveness in deep fake detection and attribution.
Results
Samples on CelebA 128×128

Samples on LSUN Bedrooms 128×128

Samples on LSUN Cats 256×256

Fingerprint visualization

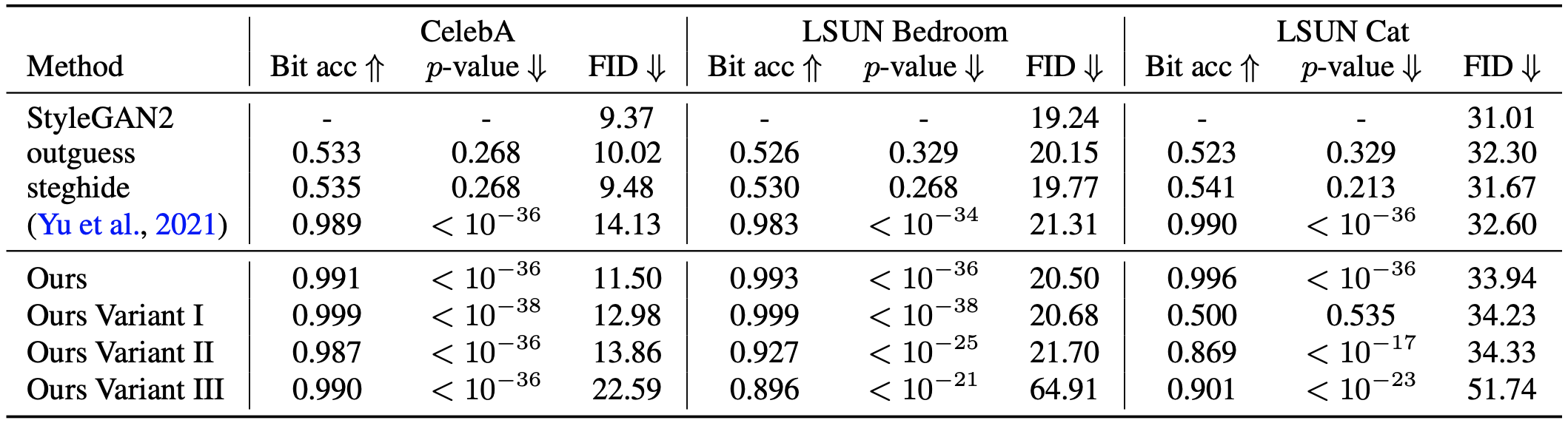
Fingerprint detection accuracy and image fidelity
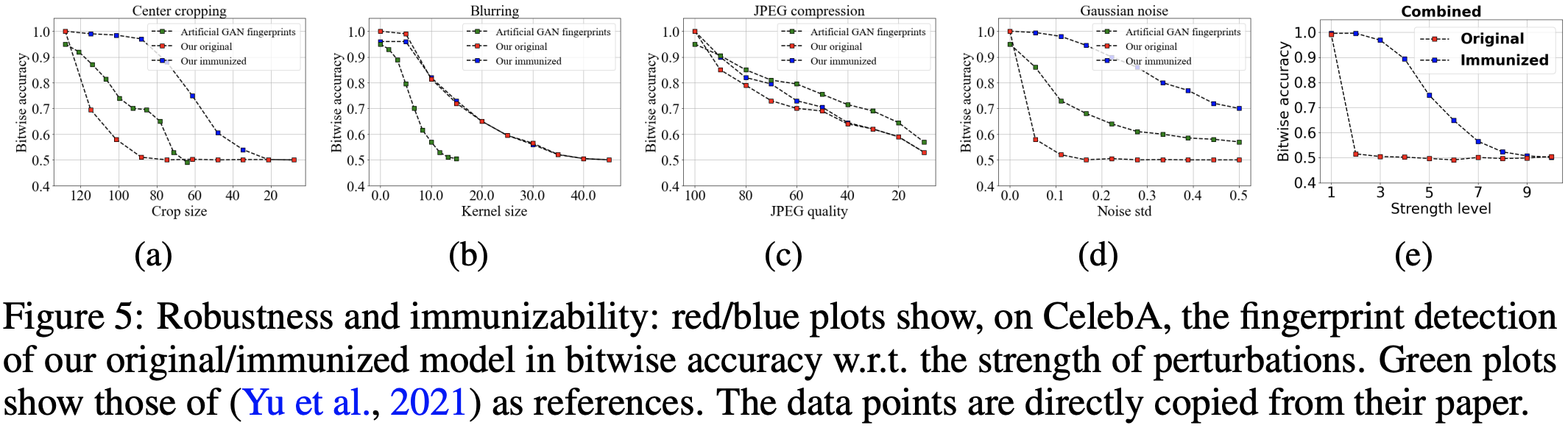
Robustness against image perturbations on CelebA 128×128
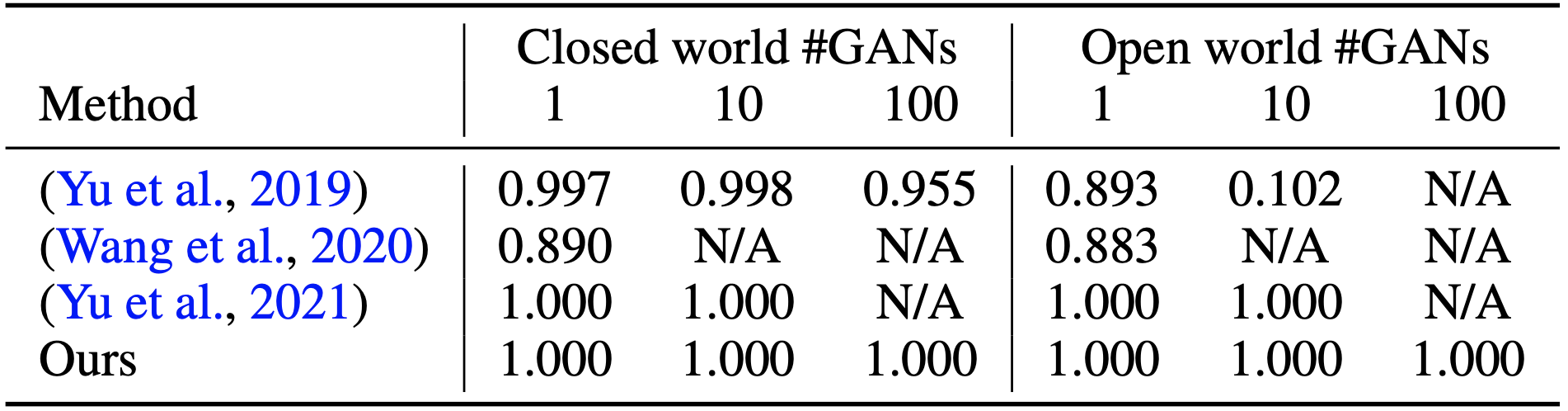
Deepfake detection and attribution accuracy
Video


Code
Press coverage

thejiangmen Academia News
Citation
@inproceedings{yu2022responsible,
title={Responsible Disclosure of Generative Models Using Scalable Fingerprinting},
author={Yu, Ning and Skripniuk, Vladislav and Chen, Dingfan and Davis, Larry and Fritz, Mario},
booktitle={International Conference on Learning Representations (ICLR)},
year={2022}
}
Acknowledgement
We thank David Jacobs, Matthias Zwicker, Abhinav Shrivastava, and Yaser Yacoob for constructive discussion and advice. Ning Yu was partially supported by Twitch Research Fellowship. Vladislav Skripniuk was partially supported by IMPRS scholarship from Max Planck Institute. This work was also supported, in part, by the US Defense Advanced Research Projects Agency (DARPA) Media Forensics (MediFor) Program under FA87501620191 and Semantic Forensics (SemaFor) Program under HR001120C0124. Any opinions, findings, conclusions, or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the DARPA. We acknowledge the Maryland Advanced Research Computing Center for providing computing resources.
Related Work
|
|
N. Yu, L. Davis, M. Fritz. Attributing fake images to gans: Learning and analyzing gan fingerprints. ICCV 2019. Comment: Our earlier work. A GAN-based Deepfake detection and attribution baseline method that extracts high/low-level and high/low-frequency image features in closed worlds. |
|
|
S.Y. Wang, O. Wang, R. Zhang, A. Owens, A. Efros. CNN-generated images are surprisingly easy to spot... for now. CVPR 2020. Comment: A CNN-based Deepfake detection baseline method that generalizes to open-world binary classification using data augmentation. |
|
|
N. Yu, V. Skripniuk, S. Abdelnabi, M. Fritz. Artificial GAN fingerprints: Rooting deepfake attribution in training data. ICCV 2021. Comment: Our earlier work. A proactive Deepfake detection and attribution baseline method that fingerprints training dataset. |
|
|
T. Karras, S. Laine, M. Aittala, J. Hellsten, J. Lehtinen, T. Aila. Analyzing and improving the image quality of stylegan. CVPR 2020. Comment: A state-of-the-art GAN method that is used as our backbone. |