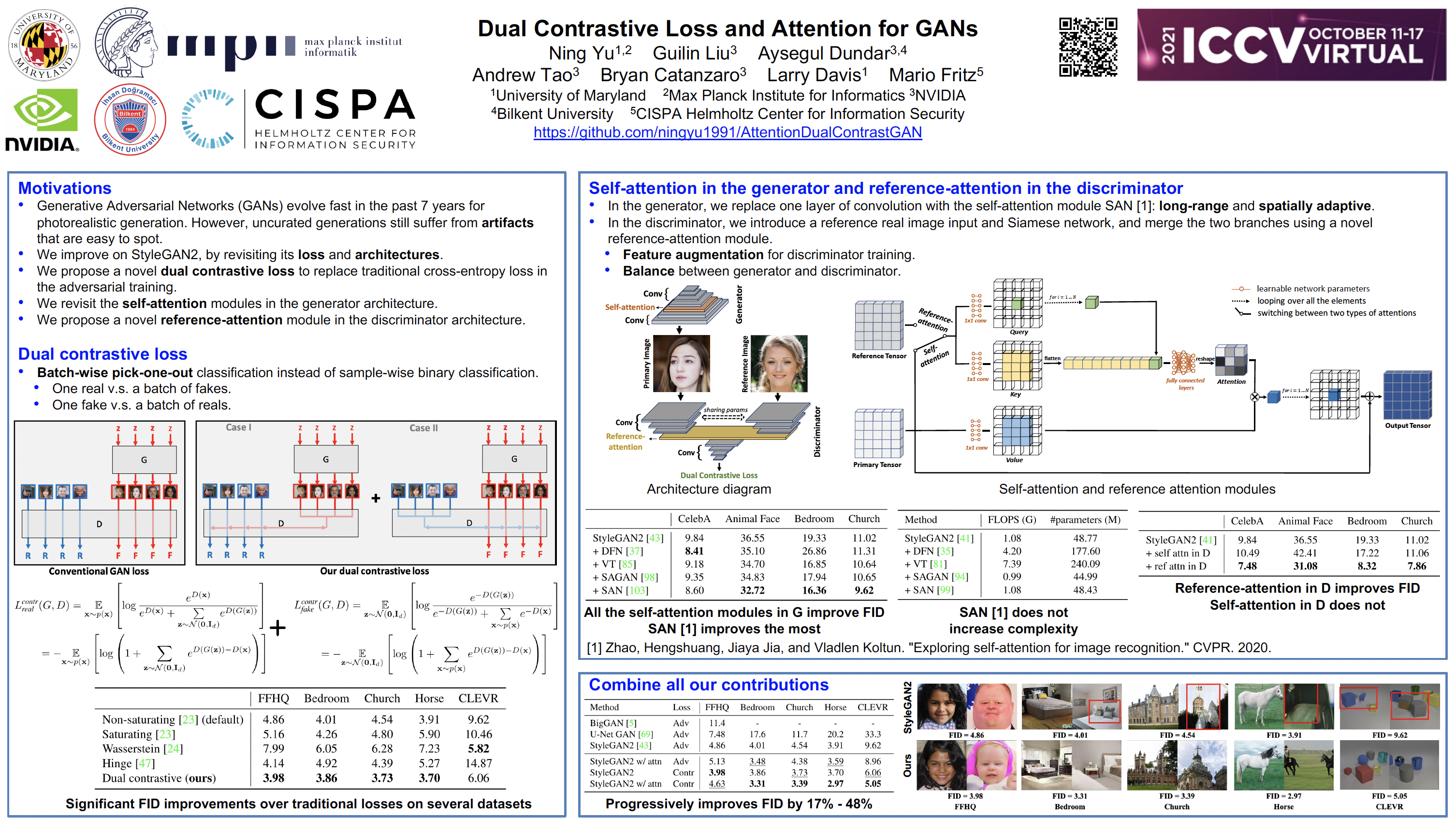
Dual Contrastive Loss and Attention for GANs
ICCV 2021
1. University of Maryland
2. Max Planck Institute for Informatics
3. NVIDIA
4. Bilkent University
5. CISPA Helmholtz Center for Information Security
5. CISPA Helmholtz Center for Information Security
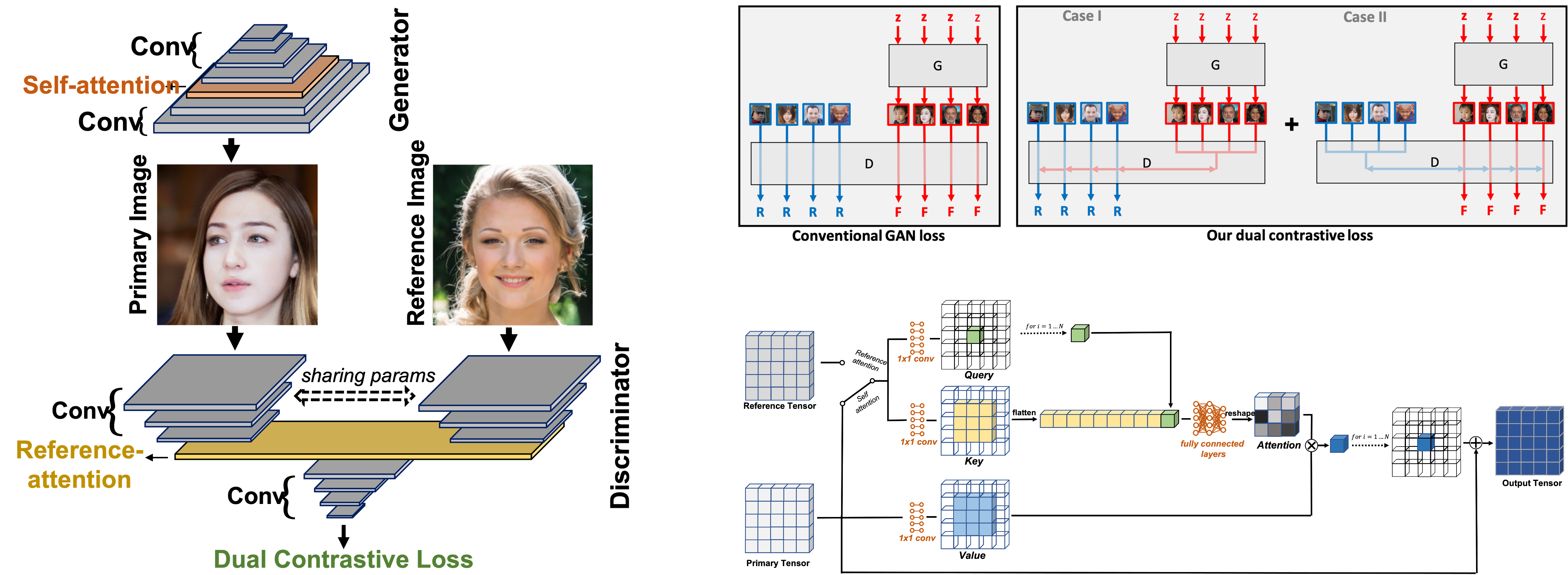
Abstract
Generative Adversarial Networks (GANs) produce impressive results on unconditional image generation when powered with large-scale image datasets. Yet generated images are still easy to spot especially on datasets with high variance (e.g. bedroom, church). In this paper, we propose various improvements to further push the boundaries in image generation. Specifically, we propose a novel dual contrastive loss and show that, with this loss, discriminator learns more generalized and distinguishable representations to incentivize generation. In addition, we revisit attention and extensively experiment with different attention blocks in the generator. We find attention to be still an important module for successful image generation even though it was not used in the recent state-of-the-art models. Lastly, we study different attention architectures in the discriminator, and propose a reference attention mechanism. By combining the strengths of these remedies, we improve the compelling state-of-the-art Frechet Inception Distance (FID) by at least 17.5% on several benchmark datasets. We obtain even more significant improvements on compositional synthetic scenes (up to 47.5% in FID).
Results
Qualitative results (see more in the paper)

Attention maps (see more in the paper)
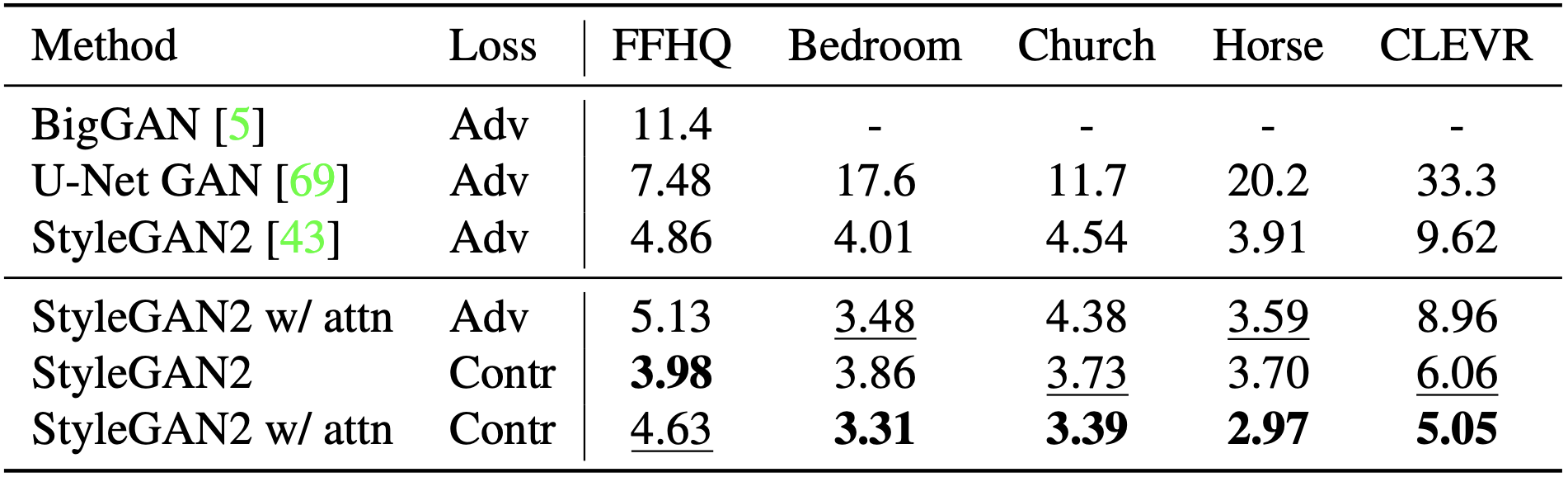
FID results
Video

Code
Press coverage

thejiangmen Academia News
Citation
@inproceedings{yu2021dual,
author={Yu, Ning and Liu, Guilin and Dundar, Aysegul and Tao, Andrew and Catanzaro, Bryan and Davis, Larry and Fritz, Mario},
title={Dual Contrastive Loss and Attention for GANs},
booktitle = {IEEE International Conference on Computer Vision (ICCV)},
year={2021}
}
Acknowledgement
We thank Tero Karras, Xun Huang, and Tobias Ritschel for constructive advice. Ning Yu was partially supported by Twitch Research Fellowship. This work was also partially supported by the DARPA SAIL-ON (W911NF2020009) program. Any opinions, findings, conclusions, or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the DARPA.